Are we there yet?
What often starts as simple databases for simple solutions grow when business is growing. Business requirements also grow over time — after all, there is only so much that can be supported by frequent reports being monitored by people at regular intervals to alert others about possible situations.
Do this, when that...
is a very easy problem to solve. For example, sending an email when the order has been placed is perhaps few lines of code. Of course, that too gets into issues when you’ve large number of concurrent orders that choke the processing due to email being sent. Solution is easy enough to simply raise an event at core processing and add asynchronous listeners to do auxiliary processing like emailing.
What about this?
Do this, when that hasn’t happened for 1 hour
Let us look at how this problem gets solved in stages :)
CRON
Hustle ye all! Keep checking. You have nothing to lose but your CPU and Memory utilization!
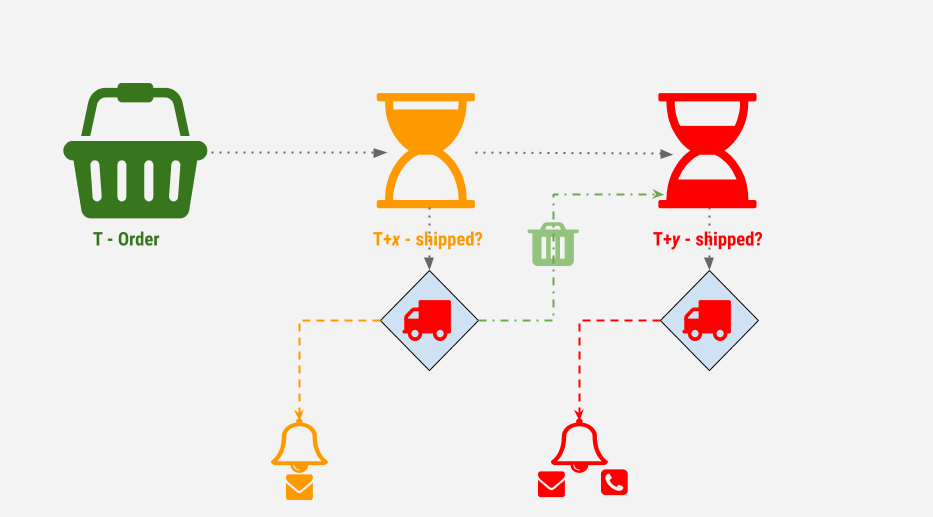
Let us consider the problem in the top image. Send an email if the order hasn’t been shipped even after X hours of placing the order.
Your data structure conceptually may be like this:
create table order(id, order_date, status, status_date,...); select * from order where status='UNSHIPPED' and now() > order_date +'x hours'::interval
So what are the problems with this?
- Same orders will get picked up at each run of the cron; and notification will fire each time. To solve it, you will end up recording previous notification and doing a not exists from that in your query.
- As data grows, the query will run slower and slower. At some point, it will become slower enough to have previous run of the cron still running when the next one comes.
- “Let us add an index on status column” — sure, it will help in the beginning; but when the data gets larger and larger, index on a column that will’ve some less than 10 distinct values won’t make magical performance gains.
- “Let us archive the closed orders into another table” — this, along with the index above will make things faster.
- “Let us add a combined index on order_date and status and change the query to use it” — yes, will make things a lot faster.
This pattern of solution and patches will spread for other such requirements and your application server will be a melee of crons.
Business will certainly come back later saying if order hasn’t been shipped even after y hours (where y > x), then raise even more alerts. And so on…
Scaling by adding more crons is going to quickly become more servers; and then more databases.
at
You don’t call me. I will call you.
Now, while most of us are familiar with cron, unix systems also have a nice
job queue command called at. It executes a given command at a particular time.
That’s it.
Let us flip the problem around from constantly scanning data into scan specific data to see if something need to be done, at specific times.
Syntax is only representational — don’t assume at command works with what is given here :)
order.created -> at "now() + x" primary_order_alert id order.created -> at "now() + y" escalated_order_alert id
Something like above. When an order is created, you add two jobs at specific times to check and raise events. Add listeners to these events to do whatever processing you need to do.
Broadly, the jobs’ logic will be like below:
o = get_order_by_id(:id) if o is not null: if o.status == 'UNSHIPPED': raise event(o)
The access by primary key is going to be as fast as it can get.
To reduce the future load on the system, we can even add a simple processing for clearing future queues.
o = get_order_by_id(:id) if o is not null: if o.status == 'UNSHIPPED': raise event(o) else: delete_at_jobs(:id)
An additional takeaway from at is also the fact that it doesn’t maintain any
audit. Your job is fired, that is cleared from the queue. Its job is to do one
thing and it does it well — like all unix utilities. A good philosophy!
A.W.T.Y — I : inspired by at
Are.We.There.Yet? at is fine, but my servers use Java/Python/…
The concept from at can be taken to a generalized database solution easily.
create table future_job ( entity_name, -- whichever table that the job should access entity_key, -- and its key first_check_at, -- when is the first check due? immutable next_check_at, -- next check? defaults to first check check_count, -- how many times has the check been done job_exec -- the class/job that needs to execute )
The job_exec follows an interface like below:
Date job_exec(FutureJob j);
The job returns a time stamp if a check needs to be done again. In case it does
return a value, the check_count is incremented and the next_check_at is set to
that value.
If it is null, simply delete the record from this table. That keeps
this table a simple cache of pending jobs. No old data here.
And your cron?
for j in get_future_job(next_check_at < now()): r = j.job_exec(j) if r is null: j.delete() else: j.next_check_at = r j.check_count += 1 j.save()
Sample job_exec for the above use case could look like:
o = get_order_by_id(j.entityKey) if (o is null) or (o.status != 'UNSHIPPED): return null if j.check_count == 0: raise primary_alert(o) return o.order_date + y::interval raise final_alert(o) return null
A.W.T.Y — II : Cops & History
This has bunch of issues still.
job_execcan be written in a poor way that it takes a lot of time. So, having a timeout guard becomes necessary.job_execcan be written to keep on adding X interval to current time to effectively make it a while loop. Having a check_count guard in the container will solve this. ie., you can add a configuration that says one entry can go up to max 5 — if the job returns a future date more than these many times, it is deleted.- Adding things way too much into the future is not in the spirit of this. Guard against it by deleting the job if the return value is in the past or if it is beyond X interval into future.
- You will want to know the time taken for each job, how many times it was attempted etc. Easy solution is to insert into a future_job_history table when we delete from our table.
- You will still’ve issues when previous cron is running when the current run starts. You will have jobs being fired twice. Then we get into same old nuisance solutions like locking a job record with some status; or adding a flag that previous one is still running then exit the current cron etc. The second option will prevent you from having crons running in multiple servers unless you add cron lock also into some single source of truth.
A.W.T.Y — III : Slots & Deterministic
So, how do we solve point #5 above?
Let us go back to requirements. Unless the system is intended to be used in extremely mission critical stuff like warfare, air traffic control etc, “do this after X interval” does not really mean “do this EXACTLY after X interval”. In most cases, we can rewrite this to “do this NOT BEFORE X interval, but within an SLA”.
That opens up a whole set of possibilities. Let us say we add a constraint that our job resolution to the nearest 15th minute. ie., Events, if applicable, will be fired after 0th, 15th, 30th and 45th minutes of every hour
ie., if your order was placed at 10:05am, and X is 3 hours, it will be picked up for checking only at 1:15pm.
In other words, there is a configuration for this, and setters for next_check_at and first_check_at rounds up the value to the slot according to the configuration.
Now, your cron is firing at exactly these slots and your logic to pick the job changes like:
# for j in get_future_job(next_check_at < now()): for j in get_future_job(next_check_at == next_slot(now())):
Solves two problems:
- There is no question of two crons picking same record.
- You can easily split this into two servers. One serves 0th and 30th minute runs and the other fires at 15th and 45th minutes.
Still has a problem though :) What if the cron servers were down for a while? Past jobs will never get picked up.
Two solutions, depending upon the kind of data you have.
- Before you start the servers again, update next_check_at for ALL jobs to next rounded up time slot.
- OR, you have a special cron that runs once in a while that has the condition for “<” instead of “==”.
This started as a 5 min conversation about an annoying problem with my colleague Ganesh Hegde. The abundance of crons for little things that had accumulated over time had led us to do multiple rounds of refactoring to make it easier to maintain; but we had to break the pattern.
We had a similar trigger to be added as part of a quick 2 day sprint and it was done using this. Working well so far. We specifically didn’t want to go looking for 3rd party solutions for this; remember — it was in between a 2 day sprint.
Neither of us could come up with a package/table name for this module that we liked. As luck would have it while we were arguing, Sadiyah Lasania, our content overlord walked by and in about 3 minutes, suggested “prescient”. So there, we named it that — mainly because it is a word seldom used by engineers :)
For large and complicated systems, the trick is going to be in computing next_check_at as fast as possible so that it is sufficiently in future and not just a static +y interval. In fact, it should be so good that your job never hits the guard on check_count. And when you have such implementations, there is nothing stopping you to make the resolution of these jobs to every minute.
Making slots using jobs lined up in file system as a quick proof-of-concept is also a great way to test it out. Simply have a folder like yymmddhhmi as a folder name for a slot and in your cron script, you convert the date to this format, cd to that directory and then do a for loop on all the files there and simply execute these.
PS: This article was posted in medium.com as well.